![]()
2.4.1. Tutoriel 4: Fonction et calcul scientifique#
Dans cette section, nous aborderons les points suivants:
Fonction
Calcul scientifique avec
NumPyBase de visualisation avec
Matplotlib
2.4.1.1. Fonction#
Pour les tâches plus longues et plus complexes, il est important d’organiser votre code en éléments réutilisables. Par exemple, si vous vous retrouvez à couper et coller les mêmes lignes de code ou des lignes similaires à plusieurs reprises, vous devez probablement définir une fonction pour encapsuler ce code et le rendre réutilisable. Un principe important de la programmation en DRY : “ne vous répétez pas”. La répétition est fastidieuse et vous expose à des erreurs. Recherchez l’élégance et la simplicité dans vos programmes.
Référence :
IBM Congnitive Class - Intro to Python (computationalcore/introduction-to-python)
CUSP UCSL bootcamp 2017 (Mohitsharma44/ucsl17)
Introduction to Python (Ryan Abernathy; https://rabernat.github.io/research_computing/intro-to-python.html)
Les fonctions sont un élément central de la programmation avancée en Python. Les fonctions prennent des entrées (“arguments”) et font quelque chose en réponse. En général, les fonctions renvoient quelque chose, mais pas toujours.
#@title **Define a Function**
def say_hello():
"""Return the word hello."""
return 'Hello'
def say_hello_to(name=None):
"""
Return the word hello to someone
"""
return 'Hello, '+str(name)
# take an optional keyword argument
def say_hello_or_hola(name, french=False):
"""Say hello in multiple languages."""
if french:
greeting = 'Bonjour '
else:
greeting = 'Hello '
return greeting + name
# flexible number of arguments
def say_hello_to_everyone(*args):
return ['Bonjour ' + str(a) for a in args]
print(say_hello())
res = say_hello()
print(res)
Hello
Hello
print(say_hello_or_hola('Frédéric', french=True)) # Saluer le recteur
print(say_hello_or_hola('Frédéric', french=False))
print(say_hello_to_everyone('Niklas', 'Valérie', 'Marie-Élodie')) # Saluer les doyens
Bonjour Frédéric
Hello Frédéric
['Bonjour Niklas', 'Bonjour Valérie', 'Bonjour Marie-Élodie']
#@title **Fonction anonyme**
mul = lambda a, b: a*b
print(mul(4,5))
20
#@title **Fonction map**
# syntaxe : map(function,iterator)
numbers = range(1, 10)
def square(num):
return num**2
list(map(square, numbers))
# L'équivalent de cette fonction est :
# result = []
# for i in range(1, 10) :
# result.append(i**2)
[1, 4, 9, 16, 25, 36, 49, 64, 81]
# On peut aussi l'écrire en une seule ligne !
list(map(lambda x : x**2, range(1, 10)))
[1, 4, 9, 16, 25, 36, 49, 64, 81]
2.4.1.1.1. Fonctions pures et fonctions impures#
Les fonctions qui ne modifient pas leurs arguments ou ne produisent pas d’autres effets secondaires sont appelées pures.
Les fonctions qui modifient leurs arguments ou provoquent d’autres actions sont appelées impures.
# Fonctions impures
def remove_last_from_list(input_list) :
input_list.pop()
names = ['Niklas', 'Valérie', 'Marie-Élodie']
remove_last_from_list(names)
print(names)
remove_last_from_list(names)
print(names)
['Niklas', 'Valérie']
['Niklas']
# Fonctions impures
def remove_last_from_list(input_list) :
input_list.pop()
names = ['Niklas', 'Valérie', 'Marie-Élodie']
remove_last_from_list(names)
print(names)
remove_last_from_list(names)
print(names)
['Niklas', 'Valérie']
['Niklas']
2.4.1.1.2. Espace de noms#
En Python, un espace de noms est une correspondance entre les noms de variables et les objets Python. On peut l’assimiler à un dictionnaire. L’espace de noms peut changer en fonction de l’endroit où vous vous trouvez dans votre programme. Les fonctions peuvent “voir” les variables dans l’espace de noms parent, mais elles peuvent également les redéfinir dans une portée privée.
Il est important que vous soyez conscient des espaces de noms dans votre code, en particulier lorsque vous traitez avec des objets mutables.
name = 'Tom' # Entrez votre nom ici
def print_name():
print(name)
def print_name_v2():
name = 'Estelle'
print(name)
print_name()
print_name_v2()
print(name)
Tom
Estelle
Tom
friends_list = ['Mario', 'Florence', 'Richard']
pet_tuple = ('Hedwig', 'Na-paw-lyon', 'Cat-hilda')
def greeter(friends, pets):
print("It's time to say hi to my friends.")
[print(f'Hi {name}! ', end="") for name in friends]
print('\nThese are the names of my pets:')
[print(f'{pet} ', end="") for pet in pets]
print('\n')
def pets_are_friends(friends, pets):
print("I consider both my pets and my friend's pets my friends!")
#add friend's pets
full_pets = pets
full_pets += ('Clifford', 'Crookshanks')
full_friends_list = friends
full_friends_list.extend(full_pets)
print('These are all my friends:')
[print(f'{name} ', end="") for name in full_friends_list]
print('\n')
greeter(friends_list, pet_tuple)
pets_are_friends(friends_list, pet_tuple)
greeter(friends_list, pet_tuple)
It's time to say hi to my friends.
Hi Mario! Hi Florence! Hi Richard!
These are the names of my pets:
Hedwig Na-paw-lyon Cat-hilda
I consider both my pets and my friend's pets my friends!
These are all my friends:
Mario Florence Richard Hedwig Na-paw-lyon Cat-hilda Clifford Crookshanks
It's time to say hi to my friends.
Hi Mario! Hi Florence! Hi Richard! Hi Hedwig! Hi Na-paw-lyon! Hi Cat-hilda! Hi Clifford! Hi Crookshanks!
These are the names of my pets:
Hedwig Na-paw-lyon Cat-hilda
2.4.1.2. Calcul scientifique avec NumPy#

Numpy est le paquetage fondamental pour le calcul scientifique avec Python
Site web : https://numpy.org/
GitHub : numpy/numpy
2.4.1.2.1. Importation et examen d’un nouveau package#
Il s’agit de notre première expérience d’importation d’un paquetage qui ne fait pas partie de la bibliothèque standard de Python.
import numpy as np
Qu’est-ce que nous venons de faire ? Nous avons importé un paquetage. Cela apporte de nouvelles variables (principalement des fonctions) dans notre interpréteur. Nous y accédons de la manière suivante.
# trouver ce qui se trouve dans notre espace de noms
dir()
['In',
'Out',
'_',
'_5',
'_6',
'__',
'___',
'__builtin__',
'__builtins__',
'__doc__',
'__loader__',
'__name__',
'__package__',
'__spec__',
'_dh',
'_i',
'_i1',
'_i10',
'_i11',
'_i12',
'_i13',
'_i14',
'_i2',
'_i3',
'_i4',
'_i5',
'_i6',
'_i7',
'_i8',
'_i9',
'_ih',
'_ii',
'_iii',
'_oh',
'exit',
'friends_list',
'get_ipython',
'greeter',
'mul',
'name',
'names',
'np',
'numbers',
'open',
'pet_tuple',
'pets_are_friends',
'print_name',
'print_name_v2',
'quit',
'remove_last_from_list',
'res',
'say_hello',
'say_hello_or_hola',
'say_hello_to',
'say_hello_to_everyone',
'square']
# trouver ce qu'il y a dans numpy
dir(np)
['False_',
'ScalarType',
'True_',
'_CopyMode',
'_NoValue',
'__NUMPY_SETUP__',
'__all__',
'__array_api_version__',
'__array_namespace_info__',
'__builtins__',
'__cached__',
'__config__',
'__dir__',
'__doc__',
'__expired_attributes__',
'__file__',
'__former_attrs__',
'__future_scalars__',
'__getattr__',
'__loader__',
'__name__',
'__numpy_submodules__',
'__package__',
'__path__',
'__spec__',
'__version__',
'_array_api_info',
'_core',
'_distributor_init',
'_expired_attrs_2_0',
'_get_promotion_state',
'_globals',
'_int_extended_msg',
'_mat',
'_msg',
'_no_nep50_warning',
'_pyinstaller_hooks_dir',
'_pytesttester',
'_set_promotion_state',
'_specific_msg',
'_type_info',
'_typing',
'_utils',
'abs',
'absolute',
'acos',
'acosh',
'add',
'all',
'allclose',
'amax',
'amin',
'angle',
'any',
'append',
'apply_along_axis',
'apply_over_axes',
'arange',
'arccos',
'arccosh',
'arcsin',
'arcsinh',
'arctan',
'arctan2',
'arctanh',
'argmax',
'argmin',
'argpartition',
'argsort',
'argwhere',
'around',
'array',
'array2string',
'array_equal',
'array_equiv',
'array_repr',
'array_split',
'array_str',
'asanyarray',
'asarray',
'asarray_chkfinite',
'ascontiguousarray',
'asfortranarray',
'asin',
'asinh',
'asmatrix',
'astype',
'atan',
'atan2',
'atanh',
'atleast_1d',
'atleast_2d',
'atleast_3d',
'average',
'bartlett',
'base_repr',
'binary_repr',
'bincount',
'bitwise_and',
'bitwise_count',
'bitwise_invert',
'bitwise_left_shift',
'bitwise_not',
'bitwise_or',
'bitwise_right_shift',
'bitwise_xor',
'blackman',
'block',
'bmat',
'bool',
'bool_',
'broadcast',
'broadcast_arrays',
'broadcast_shapes',
'broadcast_to',
'busday_count',
'busday_offset',
'busdaycalendar',
'byte',
'bytes_',
'c_',
'can_cast',
'cbrt',
'cdouble',
'ceil',
'char',
'character',
'choose',
'clip',
'clongdouble',
'column_stack',
'common_type',
'complex128',
'complex256',
'complex64',
'complexfloating',
'compress',
'concat',
'concatenate',
'conj',
'conjugate',
'convolve',
'copy',
'copysign',
'copyto',
'core',
'corrcoef',
'correlate',
'cos',
'cosh',
'count_nonzero',
'cov',
'cross',
'csingle',
'ctypeslib',
'cumprod',
'cumsum',
'cumulative_prod',
'cumulative_sum',
'datetime64',
'datetime_as_string',
'datetime_data',
'deg2rad',
'degrees',
'delete',
'diag',
'diag_indices',
'diag_indices_from',
'diagflat',
'diagonal',
'diff',
'digitize',
'divide',
'divmod',
'dot',
'double',
'dsplit',
'dstack',
'dtype',
'dtypes',
'e',
'ediff1d',
'einsum',
'einsum_path',
'emath',
'empty',
'empty_like',
'equal',
'errstate',
'euler_gamma',
'exceptions',
'exp',
'exp2',
'expand_dims',
'expm1',
'extract',
'eye',
'f2py',
'fabs',
'fft',
'fill_diagonal',
'finfo',
'fix',
'flatiter',
'flatnonzero',
'flexible',
'flip',
'fliplr',
'flipud',
'float128',
'float16',
'float32',
'float64',
'float_power',
'floating',
'floor',
'floor_divide',
'fmax',
'fmin',
'fmod',
'format_float_positional',
'format_float_scientific',
'frexp',
'from_dlpack',
'frombuffer',
'fromfile',
'fromfunction',
'fromiter',
'frompyfunc',
'fromregex',
'fromstring',
'full',
'full_like',
'gcd',
'generic',
'genfromtxt',
'geomspace',
'get_include',
'get_printoptions',
'getbufsize',
'geterr',
'geterrcall',
'gradient',
'greater',
'greater_equal',
'half',
'hamming',
'hanning',
'heaviside',
'histogram',
'histogram2d',
'histogram_bin_edges',
'histogramdd',
'hsplit',
'hstack',
'hypot',
'i0',
'identity',
'iinfo',
'imag',
'in1d',
'index_exp',
'indices',
'inexact',
'inf',
'info',
'inner',
'insert',
'int16',
'int32',
'int64',
'int8',
'int_',
'intc',
'integer',
'interp',
'intersect1d',
'intp',
'invert',
'is_busday',
'isclose',
'iscomplex',
'iscomplexobj',
'isdtype',
'isfinite',
'isfortran',
'isin',
'isinf',
'isnan',
'isnat',
'isneginf',
'isposinf',
'isreal',
'isrealobj',
'isscalar',
'issubdtype',
'iterable',
'ix_',
'kaiser',
'kron',
'lcm',
'ldexp',
'left_shift',
'less',
'less_equal',
'lexsort',
'lib',
'linalg',
'linspace',
'little_endian',
'load',
'loadtxt',
'log',
'log10',
'log1p',
'log2',
'logaddexp',
'logaddexp2',
'logical_and',
'logical_not',
'logical_or',
'logical_xor',
'logspace',
'long',
'longdouble',
'longlong',
'ma',
'mask_indices',
'matmul',
'matrix',
'matrix_transpose',
'max',
'maximum',
'may_share_memory',
'mean',
'median',
'memmap',
'meshgrid',
'mgrid',
'min',
'min_scalar_type',
'minimum',
'mintypecode',
'mod',
'modf',
'moveaxis',
'multiply',
'nan',
'nan_to_num',
'nanargmax',
'nanargmin',
'nancumprod',
'nancumsum',
'nanmax',
'nanmean',
'nanmedian',
'nanmin',
'nanpercentile',
'nanprod',
'nanquantile',
'nanstd',
'nansum',
'nanvar',
'ndarray',
'ndenumerate',
'ndim',
'ndindex',
'nditer',
'negative',
'nested_iters',
'newaxis',
'nextafter',
'nonzero',
'not_equal',
'number',
'object_',
'ogrid',
'ones',
'ones_like',
'outer',
'packbits',
'pad',
'partition',
'percentile',
'permute_dims',
'pi',
'piecewise',
'place',
'poly',
'poly1d',
'polyadd',
'polyder',
'polydiv',
'polyfit',
'polyint',
'polymul',
'polynomial',
'polysub',
'polyval',
'positive',
'pow',
'power',
'printoptions',
'prod',
'promote_types',
'ptp',
'put',
'put_along_axis',
'putmask',
'quantile',
'r_',
'rad2deg',
'radians',
'random',
'ravel',
'ravel_multi_index',
'real',
'real_if_close',
'rec',
'recarray',
'reciprocal',
'record',
'remainder',
'repeat',
'require',
'reshape',
'resize',
'result_type',
'right_shift',
'rint',
'roll',
'rollaxis',
'roots',
'rot90',
'round',
'row_stack',
's_',
'save',
'savetxt',
'savez',
'savez_compressed',
'sctypeDict',
'searchsorted',
'select',
'set_printoptions',
'setbufsize',
'setdiff1d',
'seterr',
'seterrcall',
'setxor1d',
'shape',
'shares_memory',
'short',
'show_config',
'show_runtime',
'sign',
'signbit',
'signedinteger',
'sin',
'sinc',
'single',
'sinh',
'size',
'sort',
'sort_complex',
'spacing',
'split',
'sqrt',
'square',
'squeeze',
'stack',
'std',
'str_',
'strings',
'subtract',
'sum',
'swapaxes',
'take',
'take_along_axis',
'tan',
'tanh',
'tensordot',
'test',
'testing',
'tile',
'timedelta64',
'trace',
'transpose',
'trapezoid',
'trapz',
'tri',
'tril',
'tril_indices',
'tril_indices_from',
'trim_zeros',
'triu',
'triu_indices',
'triu_indices_from',
'true_divide',
'trunc',
'typecodes',
'typename',
'typing',
'ubyte',
'ufunc',
'uint',
'uint16',
'uint32',
'uint64',
'uint8',
'uintc',
'uintp',
'ulong',
'ulonglong',
'union1d',
'unique',
'unique_all',
'unique_counts',
'unique_inverse',
'unique_values',
'unpackbits',
'unravel_index',
'unsignedinteger',
'unstack',
'unwrap',
'ushort',
'vander',
'var',
'vdot',
'vecdot',
'vectorize',
'void',
'vsplit',
'vstack',
'where',
'zeros',
'zeros_like']
# trouver la version que nous avons
np.__version__
'2.1.2'
Il est impossible d’apprendre explicitement chacune de ces fonctions. C’est pourquoi la documentation de numpy est cruciale !
2.4.1.2.2. NDArrays#
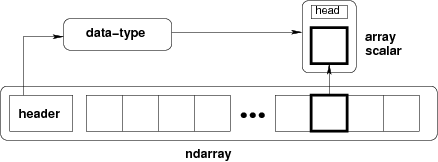
La classe de base est le numpy ndarray (tableau à n dimensions).
La principale différence entre un tableau numpy et un conteneur de données plus général comme list est la suivante :
Les tableaux Numpy peuvent avoir N dimensions (alors que les
listes,tuples, etc. n’en ont qu’une).Les tableaux Numpy contiennent des valeurs du même type de données (par exemple
int,float), alors que leslistespeuvent contenir n’importe quoi.Numpy optimise les opérations numériques sur les tableaux. Numpy est rapide !
from IPython.display import Image
Image(url='http://docs.scipy.org/doc/numpy/_images/threefundamental.png')
# créer un tableau à partir d'une liste
a = np.array([9,0,2,1,0])
# trouver le type de données
a.dtype
dtype('int64')
# trouver la forme
a.shape
(5,)
# quelle est la forme
type(a.shape)
tuple
# un autre tableau avec un type de données et une forme différents
b = np.array([[5,3,1,9],[9,2,3,0]], dtype=np.float64)
# vérifier le type et la forme
b.dtype, b.shape
(dtype('float64'), (2, 4))
Note
La dimension qui varie le plus rapidement est la dernière ! Le niveau extérieur de la hiérarchie est la première dimension. (C’est ce qu’on appelle l’indexation de type “c”)
2.4.1.2.3. Création de tableaux#
Il existe de nombreuses façons de créer des tableaux.
# créer des tableaux uniformes
c = np.zeros((9,9))
d = np.ones((3,6,3), dtype=np.complex128)
e = np.full((3,3), np.pi)
e = np.ones_like(c)
f = np.zeros_like(d)
arange fonctionne de manière très similaire à range, mais il remplit le tableau “impatiemment” (c’est-à-dire immédiatement), plutôt que de générer les valeurs lors de l’itération.
np.arange(10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
arange est inclusif à gauche, exclusif à droite, tout comme range,
mais fonctionne aussi avec les nombres à virgule flottante.
np.arange(2,4,0.25)
array([2. , 2.25, 2.5 , 2.75, 3. , 3.25, 3.5 , 3.75])
Un besoin fréquent est de générer un tableau de N nombres, espacés régulièrement entre deux valeurs. C’est à cela que sert linspace.
np.linspace(2,4,20)
array([2. , 2.10526316, 2.21052632, 2.31578947, 2.42105263,
2.52631579, 2.63157895, 2.73684211, 2.84210526, 2.94736842,
3.05263158, 3.15789474, 3.26315789, 3.36842105, 3.47368421,
3.57894737, 3.68421053, 3.78947368, 3.89473684, 4. ])
#espacé logarithmiquement
np.logspace(1,2,10)
array([ 10. , 12.91549665, 16.68100537, 21.5443469 ,
27.82559402, 35.93813664, 46.41588834, 59.94842503,
77.42636827, 100. ])
Numpy dispose également de quelques utilitaires pour nous aider à générer des tableaux multidimensionnels. meshgrid crée des tableaux 2D à partir d’une combinaison de tableaux 1D.
x = np.linspace(-2*np.pi, 2*np.pi, 100)
y = np.linspace(-np.pi, np.pi, 50)
xx, yy = np.meshgrid(x, y)
xx.shape, yy.shape
((50, 100), (50, 100))
2.4.1.2.4. Indexation#
L’indexation de base est similaire aux listes
# obtenir quelques éléments individuels de xx
xx[0,0], xx[-1,-1], xx[3,-5]
(np.float64(-6.283185307179586),
np.float64(6.283185307179586),
np.float64(5.775453161144872))
# obtenir des lignes et des colonnes entières
xx[0].shape, xx[ :,-1].shape
((100,), (50,))
# obtenir des plages
xx[3:10,30:40].shape
(7, 10)
Il existe de nombreuses méthodes avancées d’indexation des tableaux. Vous pouvez [en prendre connaissance] (https://numpy.org/doc/stable/reference/arrays.indexing.html) dans le manuel. Voici un exemple.
# utiliser un tableau booléen comme index
idx = xx<0
yy[idx].shape
(2500,)
# le tableau a été aplati
xx.ravel().shape
(5000,)
2.4.1.3. Base de visualisation avec Matplotlib#
Il peut être difficile de travailler avec de grands tableaux sans rien voir de nos yeux ! Nous allons maintenant utiliser Matplotlib pour commencer à visualiser ces tableaux. Pour l’instant, nous ne ferons qu’effleurer la surface de Matplotlib. Nous irons beaucoup plus loin dans le prochain carnet.
from matplotlib import pyplot as plt
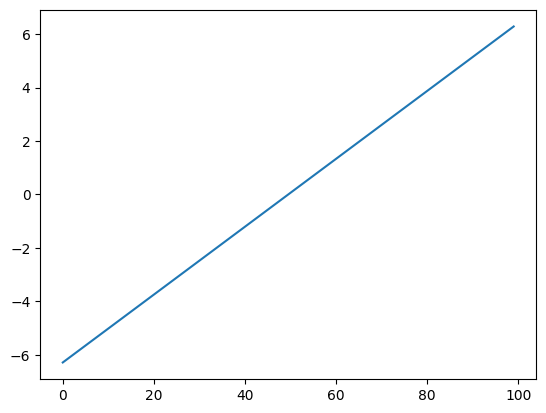
Pour tracer un tableau 1D sous forme de ligne, nous utilisons la commande plot.
plt.plot(x)
[<matplotlib.lines.Line2D at 0x7f035cd3fc50>]
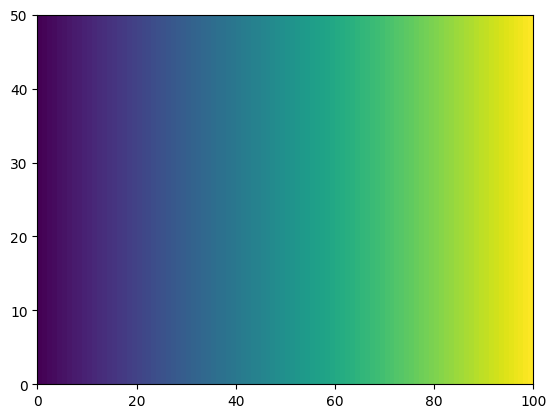
Il existe de nombreuses façons de visualiser des données en 2D. Ici, nous utilisons pcolormesh.
plt.pcolormesh(xx)
<matplotlib.collections.QuadMesh at 0x7f035cdb0190>
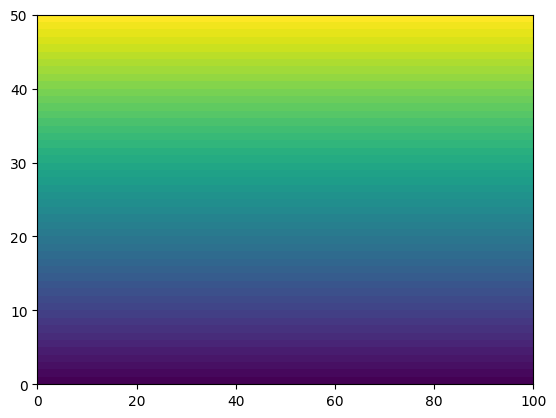
plt.pcolormesh(yy)
<matplotlib.collections.QuadMesh at 0x7f035ab0a690>
2.4.1.3.1. Opérations sur les tableaux#
Il existe un grand nombre d’opérations sur les tableaux. Tous les opérateurs arithmétiques familiers sont appliqués élément par élément.
2.4.1.3.1.1. Mathématiques de base#
f = np.sin(xx) * np.cos(0.5*yy)
plt.pcolormesh(f)
<matplotlib.collections.QuadMesh at 0x7f035ab40110>
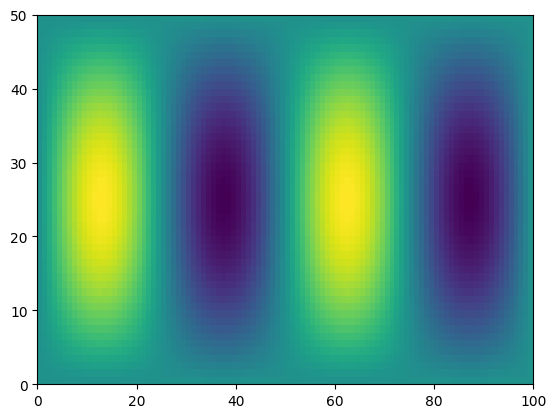
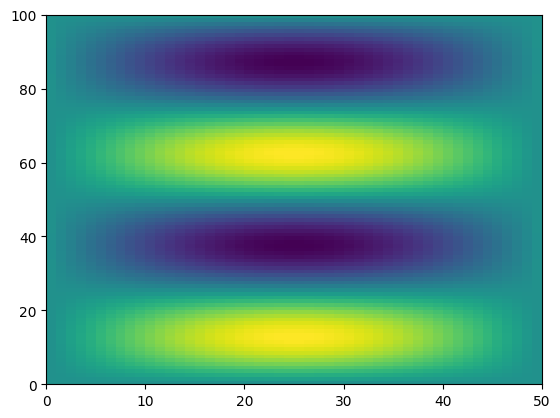
2.4.1.3.1.2. Manipulation des dimensions des tableaux#
La permutation de l’ordre des dimensions s’effectue en appelant transpose.
f_transposed = f.transpose()
plt.pcolormesh(f_transposed)
<matplotlib.collections.QuadMesh at 0x7f035cde2090>
Nous pouvons également modifier manuellement la forme d’un tableau… à condition que la nouvelle forme ait le même nombre d’éléments.
g = np.reshape(f, (8,9))
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[41], line 1
----> 1 g = np.reshape(f, (8,9))
File /opt/hostedtoolcache/Python/3.11.10/x64/lib/python3.11/site-packages/numpy/_core/fromnumeric.py:328, in reshape(a, shape, order, newshape, copy)
326 if copy is not None:
327 return _wrapfunc(a, 'reshape', shape, order=order, copy=copy)
--> 328 return _wrapfunc(a, 'reshape', shape, order=order)
File /opt/hostedtoolcache/Python/3.11.10/x64/lib/python3.11/site-packages/numpy/_core/fromnumeric.py:57, in _wrapfunc(obj, method, *args, **kwds)
54 return _wrapit(obj, method, *args, **kwds)
56 try:
---> 57 return bound(*args, **kwds)
58 except TypeError:
59 # A TypeError occurs if the object does have such a method in its
60 # class, but its signature is not identical to that of NumPy's. This
(...)
64 # Call _wrapit from within the except clause to ensure a potential
65 # exception has a traceback chain.
66 return _wrapit(obj, method, *args, **kwds)
ValueError: cannot reshape array of size 5000 into shape (8,9)
Toutefois, soyez prudent lorsque vous remodelez des données ! Vous risquez de perdre accidentellement la structure des données.
g = np.reshape(f, (200,25))
plt.pcolormesh(g)
Il est également possible de “carreler” (=”tile”) un tableau pour le répéter plusieurs fois.
f_tiled = np.tile(f,(3, 2))
plt.pcolormesh(f_tiled)
Un autre besoin courant est d’ajouter une dimension supplémentaire à un tableau. Ceci peut être réalisé en indexant avec None.
x.shape
x[None, :].shape
x[None, :, None, None].shape
2.4.1.3.2. Broadcasting#
Les tableaux avec lesquels nous voulons travailler n’ont pas tous la même taille. Une approche serait d‘“étendre” manuellement nos tableaux pour qu’ils aient tous la même taille, par exemple en utilisant tile. Broadcasting est un moyen plus efficace de multiplier des tableaux de tailles différentes Numpy a des règles spécifiques pour le fonctionnement de la diffusion. Elles peuvent être déroutantes mais valent la peine d’être apprises si vous avez l’intention de travailler souvent avec des données Numpy.
Le concept de base de Broadcasting consiste à indiquer à Numpy les dimensions qui sont censées s’aligner les unes sur les autres.
Image(url='http://scipy-lectures.github.io/_images/numpy_broadcasting.png',
width=720)
Les dimensions sont automatiquement alignées en commençant par la dernière dimension. Si les deux dernières dimensions ont la même longueur, les deux tableaux peuvent être diffusés (broadcast).
print(f.shape, x.shape)
g = f * x
print(g.shape)
plt.pcolormesh(g)
Cependant, si les deux dernières dimensions ne sont pas identiques, Numpy ne peut pas le déterminer automatiquement.
# multiplier f par y
print(f.shape, y.shape)
h = f * y
Nous pouvons aider numpy en ajoutant une dimension supplémentaire à y à la fin. Les dimensions de la longueur 50 s’aligneront alors.
print(f.shape, y[:, None].shape)
h = f * y[:, None]
print(h.shape)
plt.pcolormesh(h)
2.4.1.3.3. Opérations de réduction#
Dans l’analyse de données scientifiques, nous partons généralement d’un grand nombre de données et nous voulons les réduire afin de créer des graphiques ou des tableaux récapitulatifs. Les opérations qui réduisent la taille des tableaux numpy sont appelées “réductions”. Il existe de nombreuses opérations de réduction différentes. Nous examinerons ici quelques-unes des plus courantes.
# sum
g.sum()
# mean
g.mean()
# standard deviation
g.std()
Une propriété clé des réductions numpy est la possibilité d’opérer sur un seul axe.
# appliquer sur un seul axe
g_ymean = g.mean(axis=0)
g_xmean = g.mean(axis=1)
plt.plot(x, g_ymean)
plt.plot(g_xmean, y)
2.4.1.3.4. Fichiers de données#
Il peut être utile d’enregistrer les données numpy dans des fichiers.
np.save('g.npy', g)
Attention
Les fichiers Numpy .npy sont un moyen pratique de stocker des données temporaires, mais ils ne sont pas considérés comme un format d’archivage robuste. Plus tard, nous découvrirons NetCDF, le format recommandé pour stocker les données terrestres et environnementales
g_loaded = np.load('g.npy')
np.testing.assert_equal(g, g_loaded)